Abstract
Existing approaches to video understanding, mainly designed for short videos from a third-person perspective, are limited in their applicability in certain fields, such as robotics. In this paper, we delve into open-ended question-answering (QA) in long, egocentric videos, which allows individuals or robots to inquire about their own past visual experiences. This task presents unique challenges, including the complexity of temporally grounding queries within ex tensive video content, the high resource demands for precise data annotation, and the inherent difficulty of evaluating open-ended answers due to their ambiguous nature. Our proposed approach tackles these challenges by (i) integrating query grounding and answering within a unified model to reduce error propagation; (ii) employing large language models for efficient and scalable data synthesis; and (iii) introducing a close-ended QA task for evaluation, to manage answer ambiguity. Extensive experiments demonstrate the effectiveness of our method, which also achieves state- of-the-art performance on the QAEgo4D and Ego4D-NLQ benchmarks. We plan to publicly release the codes, model, and constructed datasets for future research.
Method
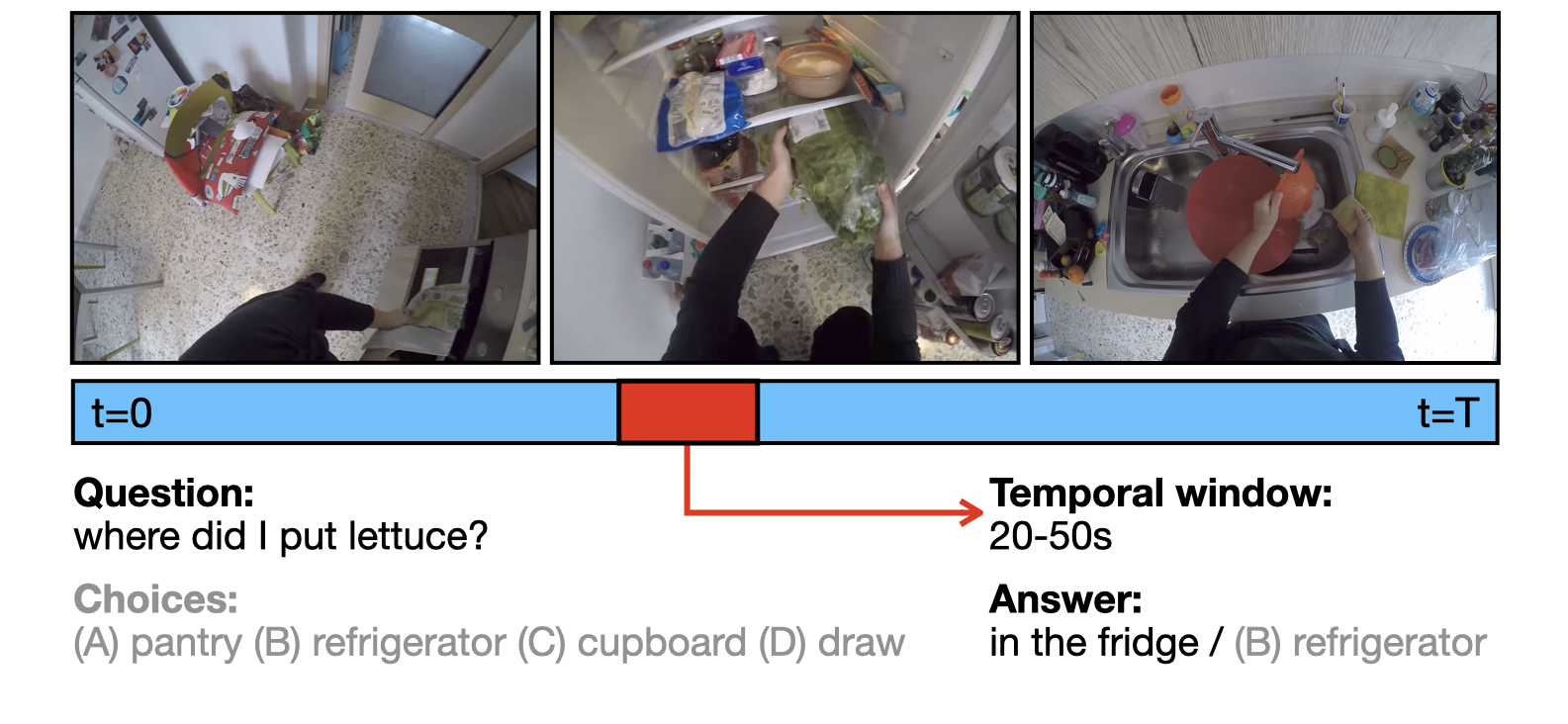
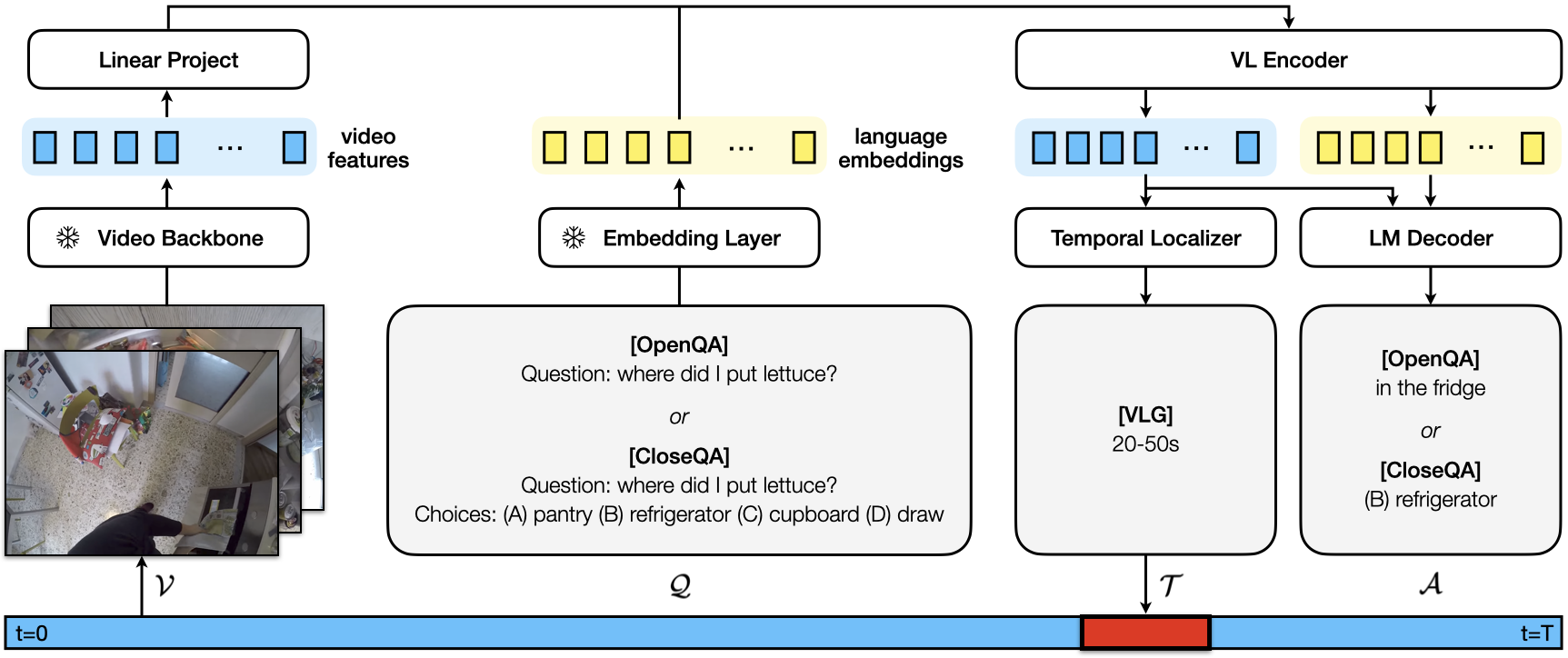
This paper investigates the problem of grounded question answering in long egocentric videos, i.e., the simultaneous localization and answering of questions. Our model, GroundVQA, addresses three tasks: OpenQA, CloseQA, and VLG. The model processes a video V and a question Q, to reason about the relevant temporal window T and the answer A. Initially, a frozen video backbone encodes V and maps it into the language embedding space. Simultaneously, Q undergoes tokenization and is transformed through an embedding layer. These video and question embeddings are then fused using a visual-language encoder. Finally, a temporal localizer uses the resulting video features to predict T , whereas a language decoder utilizes both video and question features, as provided by the VL encoder, to generate A.
We use Llama2 to generate QA pairs from consecutive narration sentences. (A) First, we generate question-answer pairs using consecutive narration sentences from Ego4D. (B) Next, we generate three plausible yet incorrect answers for each question-answer pair to construct data for the CloseQA task. We provide in-context examples to enhance the generation quality. Consequently, we have created EgoTimeQA, a grounded QA dataset containing 5,389 egocentric videos and 303K samples.

Results
Comparisons with state-of-the-art models on the QaEgo4D and NLQv2 test sets:

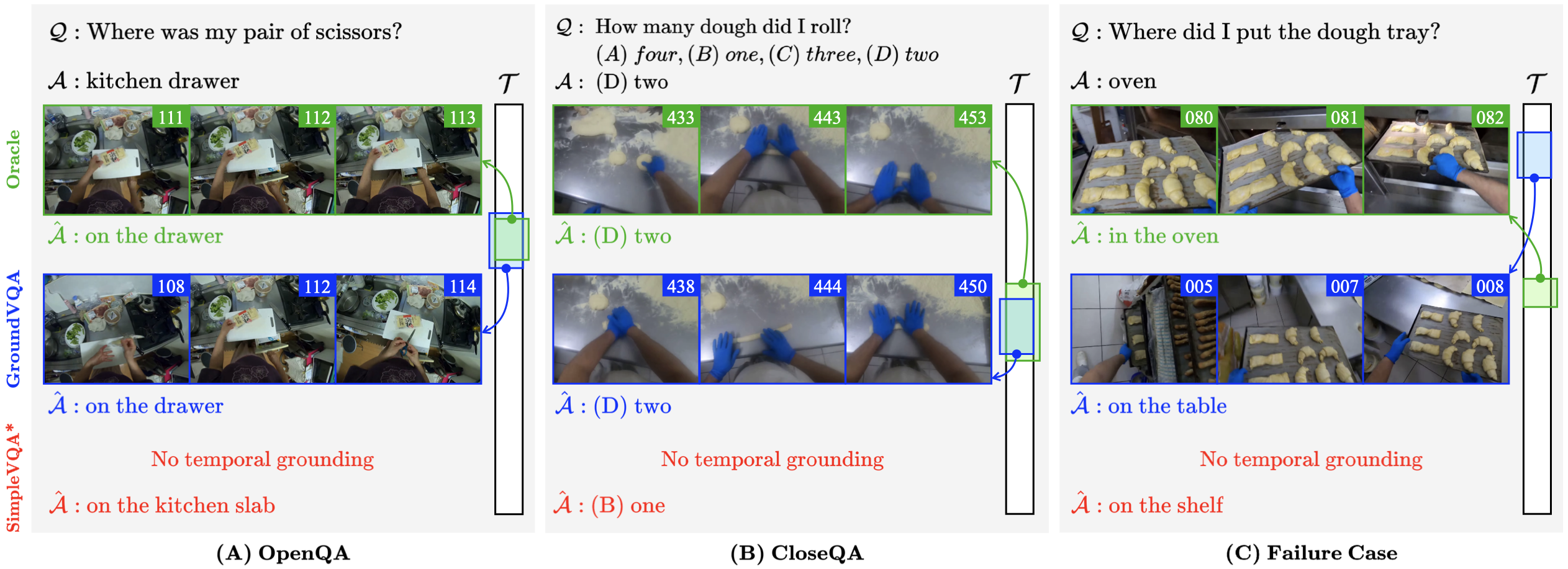
Visualizations: