|
Hi, I am a fourth-year PhD candidate at Shanghai Jiao Tong University (SJTU), where I am fortunate to be advised by Prof. Weidi Xie. My research focuses on video understanding and multimodal learning, driven by a passion for exploring the unknowns in these fields. Before joining SJTU, I earned my master's and bachelor's degrees from Beihang University (BUAA). During this period, I explored video background music generation and visual object tracking under the guidance of Prof. Si Liu. I’m always eager to connect, exchange ideas, and collaborate on innovative research. Please feel free to reach out! Email / CV / Github / Google Scholar |

|
|
|
|
|
|
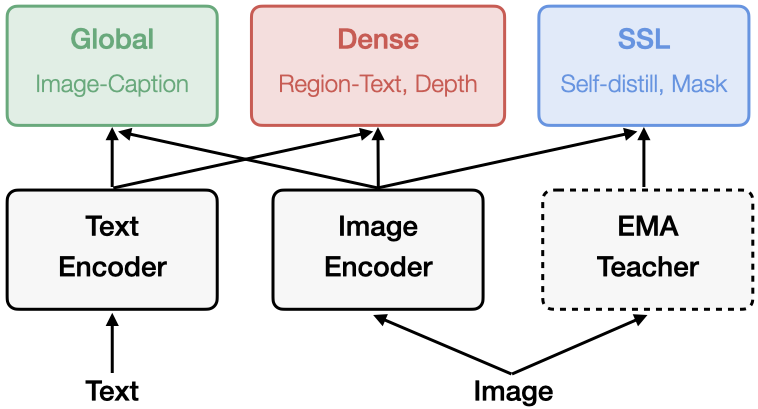
Shangzhe Di, Zhonghua Zhai, Weidi Xie In submission. paper / code / bibtex Multitask pre-training can yield scalable general-purpose visual representations. |
|
|
Yudi Shi, Shangzhe Di, Qirui Chen, Qinian Wang, Jiayin Cai, Xiaolong Jiang, Yao Hu, Weidi Xie In CVPR Workshop, 2026. paper / project page / code / bibtex |
|
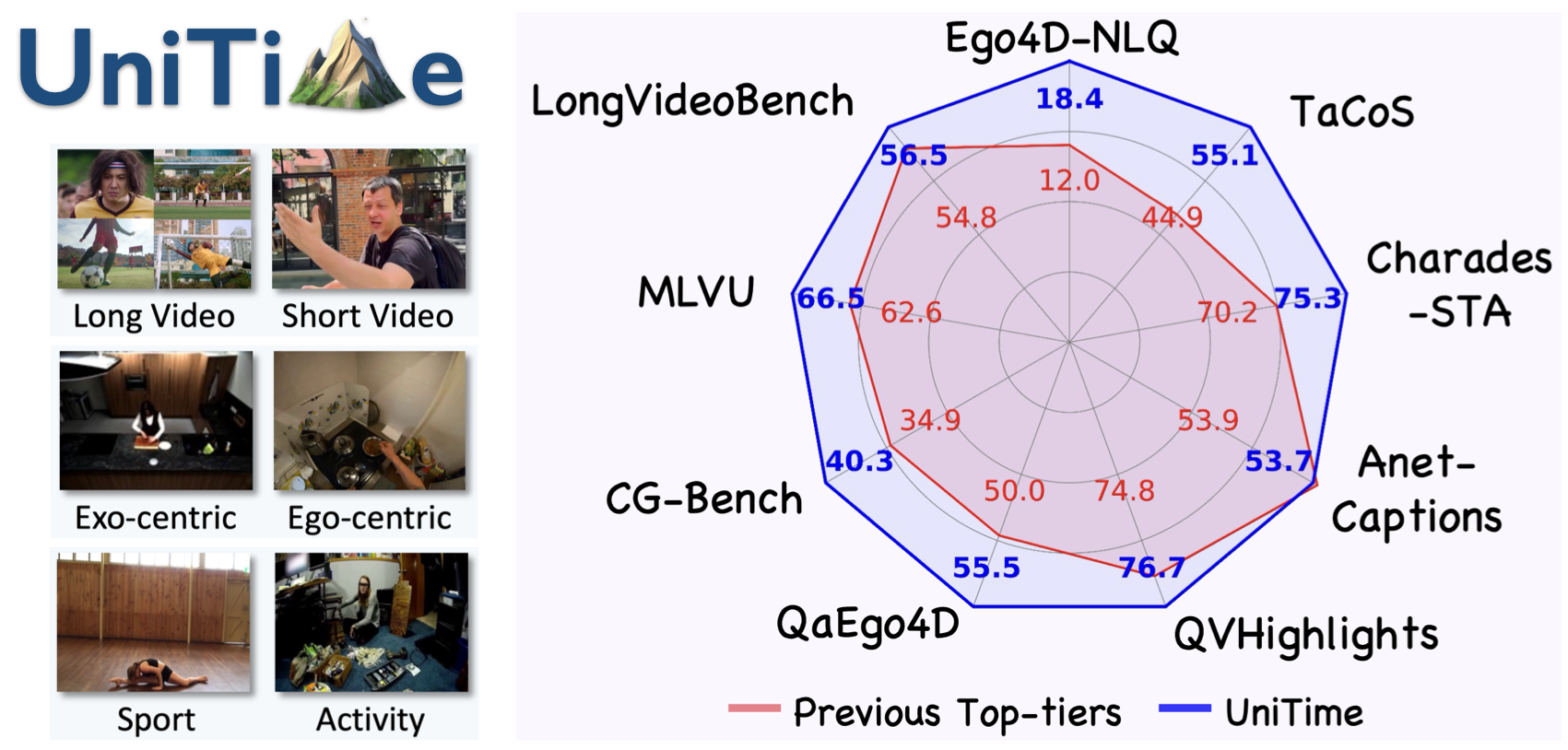
Zeqian Li, Shangzhe Di, Zhonghua Zhai, Weilin Huang, Yanfeng Wang, Weidi Xie In NeurIPS, 2025. paper / project page / code / bibtex Towards universal video grounding with superior accuracy, generalizability, and robustness. |
|
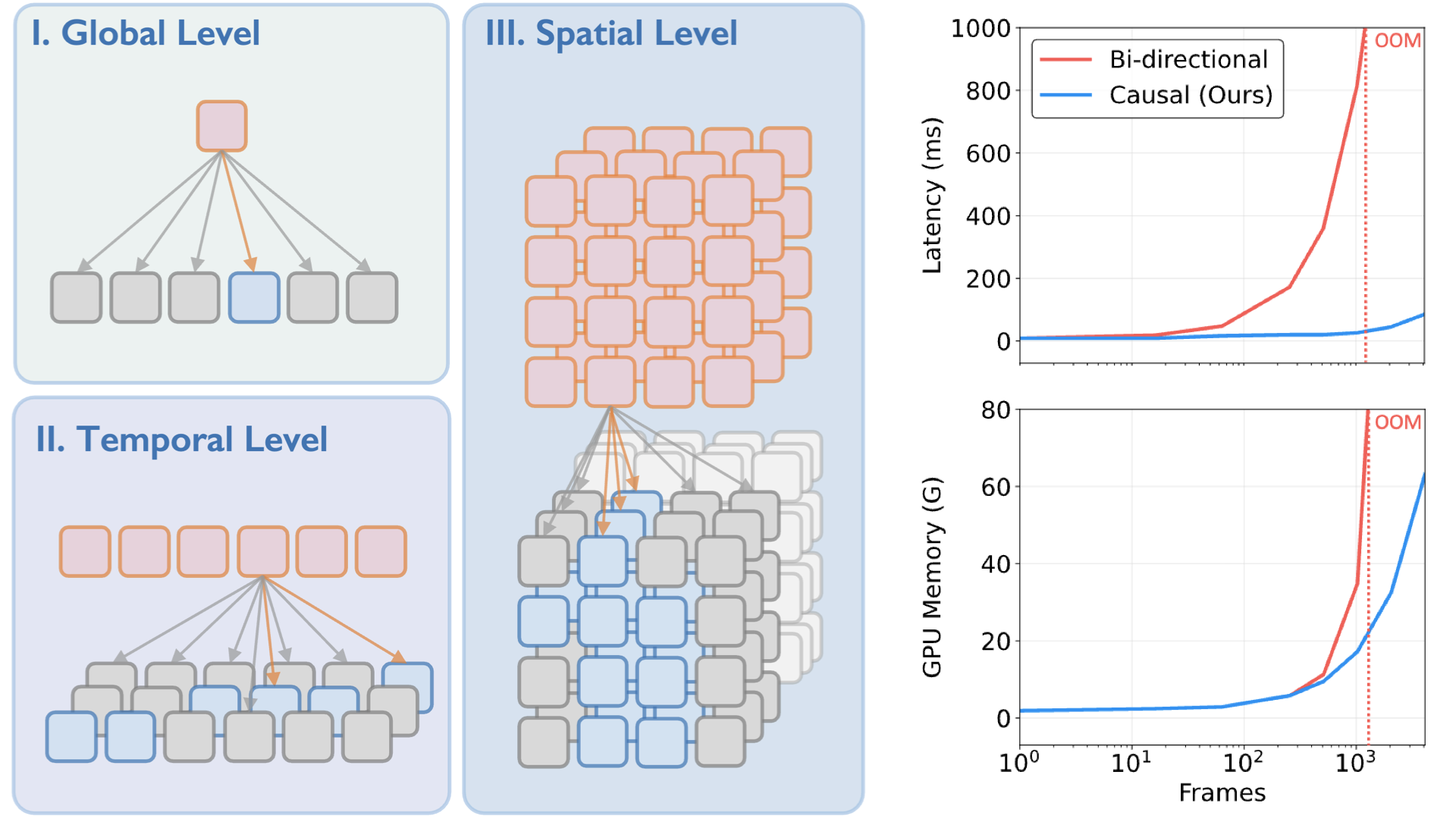
Yibin Yan*, Jilan Xu*, Shangzhe Di, Yikun Liu, Yudi Shi, Qirui Chen, Zeqian Li, Yifei Huang, Weidi Xie In ICCV, 2025. (Oral) paper / project page / code / bibtex Learn streaming video representations of various granularities via multitask training, including global (retrieval, action recognition), temporal (grounding), and spatial (segmentation) objectives. |
|
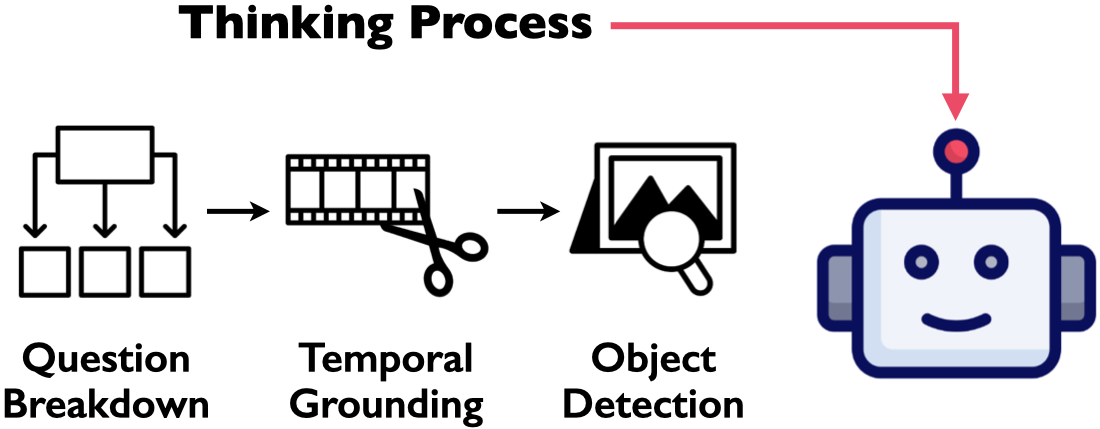
Yudi Shi, Shangzhe Di, Qirui Chen, Weidi Xie In CVPR, 2025. paper / project page / code / bibtex Distill multi-step reasoning and spatial-temporal understanding into a generative Video-LLM. |
|
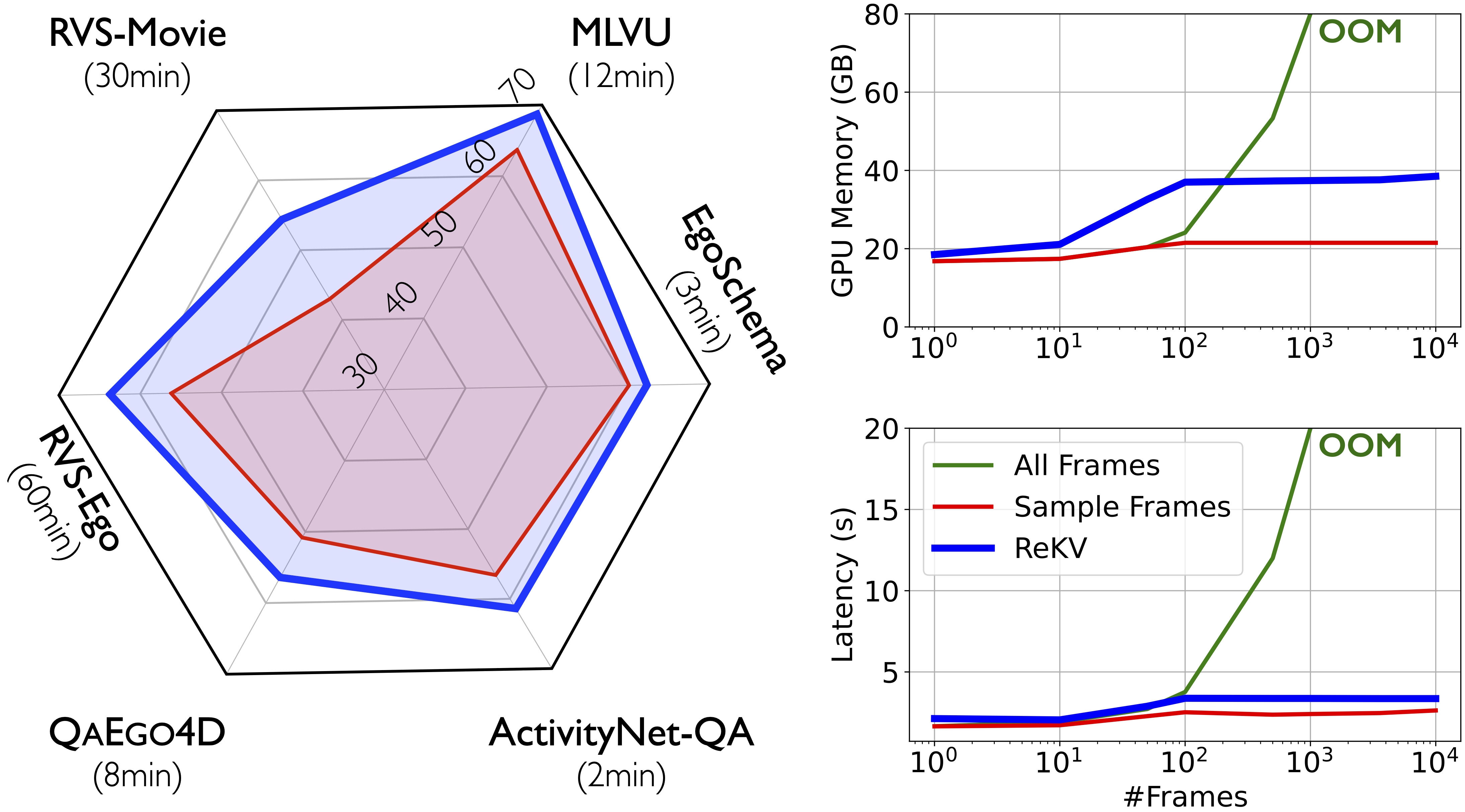
Shangzhe Di, Zhelun Yu, et al. In ICLR, 2025. paper / code / bibtex A training-free approach enabling Video-LLMs for streaming video question-answering. |

|
Qirui Chen, Shangzhe Di, Weidi Xie In AAAI, 2025. paper / project page / code / bibtex Pinpoint scattered visual evidence in long egocentric videos while responding to questions. |

|
Shangzhe Di, Weidi Xie In CVPR, 2024. paper / project page / code / bibtex Simultaneous query grounding and answering in long, egocentric videos. |
|
Shangzhe Di*, Zeren Jiang*, Si Liu, Zhaokai Wang, Leyan Zhu, Zexin He, Hongming Liu, Shuicheng Yan In ACM MM, 2021. (Best Paper Award) paper / project page / code / colab notebook / bibtex The first satisfying method for video background music generation. |
|
|
{kind=link}
The website template is borrowed from here.